15行代码5秒搞定上亿规模整数排序
年末大家闲的蛋疼,有同事抛出一个题目切磋切磋。
给定一个包含有一亿随机整数的数组,要求对其排序,越快越好,请给出算法。(随意发挥,对内存无要求)
之后一哥们给出一个大规模数据排序的Fork/Join解法,基本思路如下:“从样本中任意取一个元素(比如最后一个元素),将整个数组Array分为两部分Array_1和Array_2,其中Array_1的每个元素比这个数大,Array_2的每个元素比这个数小”,再分别对Array_1和Array_2执行上述操作,直到每个小array_n_n的规模到达某个量级(比如5k个),再用基本的排序算法对每个小array_n_n排序,最后合并整个结果集。
经测试,别说亿级,即使样本规模缩小到百万级,此解法的效率也是极其低下,当然这不是Map/Reduce擅长的场景,不是他的菜,我们只是玩玩,切磋切磋而已。
后来我想到一个自以为比较不错的方法,记录下来以备用。当然此法也是有缺陷的,稍后再说,思路如下:不好意思,拿铁道部举个例子,假设样本数组中的数值表示的是某人回家的火车的车次编码,比如第一个元素是302,其代表这个人要坐302次列车回家见妈,这一亿个样本数据就是一亿个人,每个人背上写着回家要坐的火车车次号码编码(不是座位号,仅仅是哪趟车),比如你是1404次列车,他是302次列车,我也是1404次,首先请铁道部车准备好一亿辆从小到大编好号码的火车(艾玛,铁道部赚大了),1次,2次。。302次。。。1404次一字排开,然后大家按队伍先后一个个上火车(当然也可以一股脑往上挤,那就是并发啦),最后铁道部按照火车次序挨个说,你们都是使用插件抢的票,统统下车,这按照火车次序挨个清理出来的人即是排序结果。
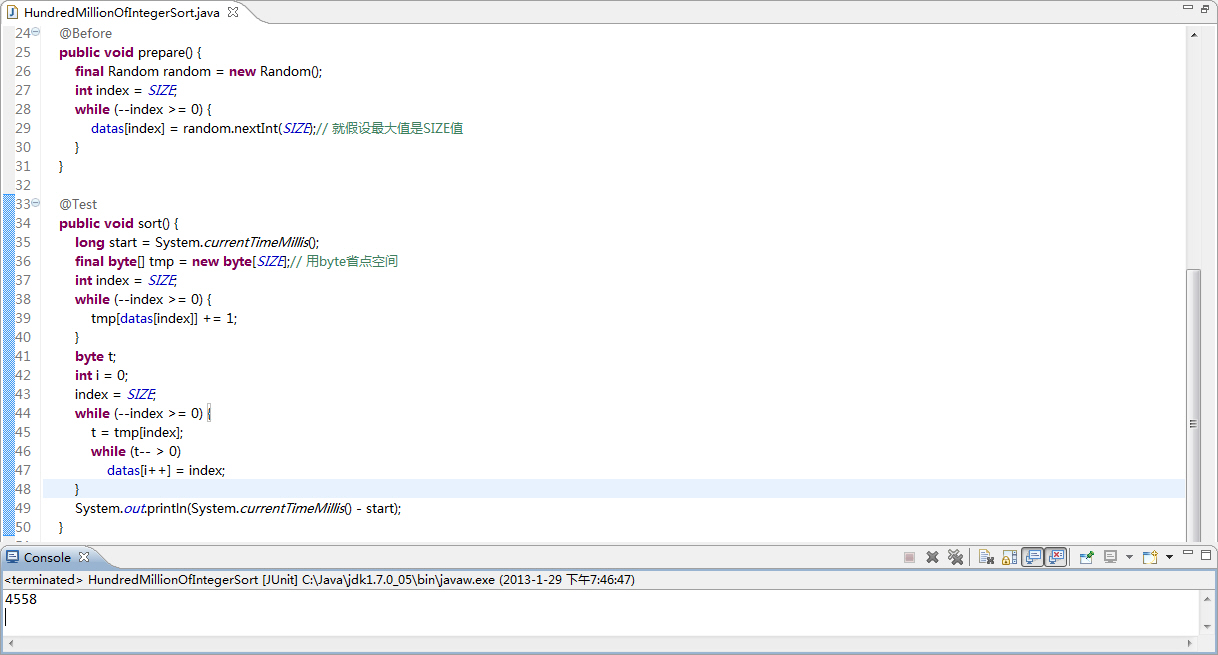
大家都是码农,就直接上代码:
|
上述代码算头算尾一共15行,没错吧,我不是标题党!我在公司机器上(32位 win server 2003 3G内存 2核CPU)跑基本在5.5秒左右即可完成排序,回家在自己机器上(64位win7旗舰版 4核CPU 4G内存)试了很多遍,基本都是在4.5秒左右便可以完成。
当然,这算法是有缺陷的,辅助数组byte[] tmp的初始程度应该是样本数据中的绝对值的最大值,你必须先想办法弄到最大值,额。。。如果你是高富帅可以new个Integer.MAX_VALUE的辅助数组。另外,有同事说你这个算法要求样本必须是正数才行,我觉得包含负数也OK啊,再弄个byte[] tmp2,针对负数取绝对值反着排,分而治之再合并。代码见附件,欢迎拍砖。
ps:首先,我承认我是标题党,我就是为了引起大家注意的,谁让咱刚开始写博客,人气低呢。